如果您无法下载资料,请参考说明:
1、部分资料下载需要金币,请确保您的账户上有足够的金币
2、已购买过的文档,再次下载不重复扣费
3、资料包下载后请先用软件解压,在使用对应软件打开
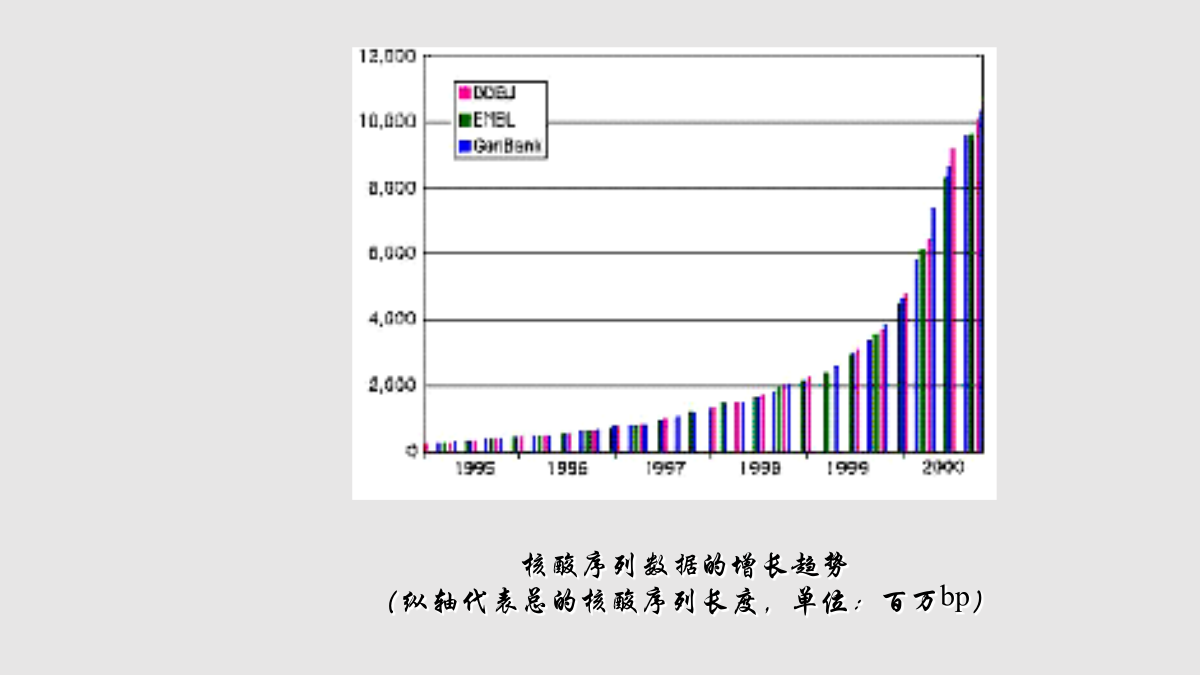
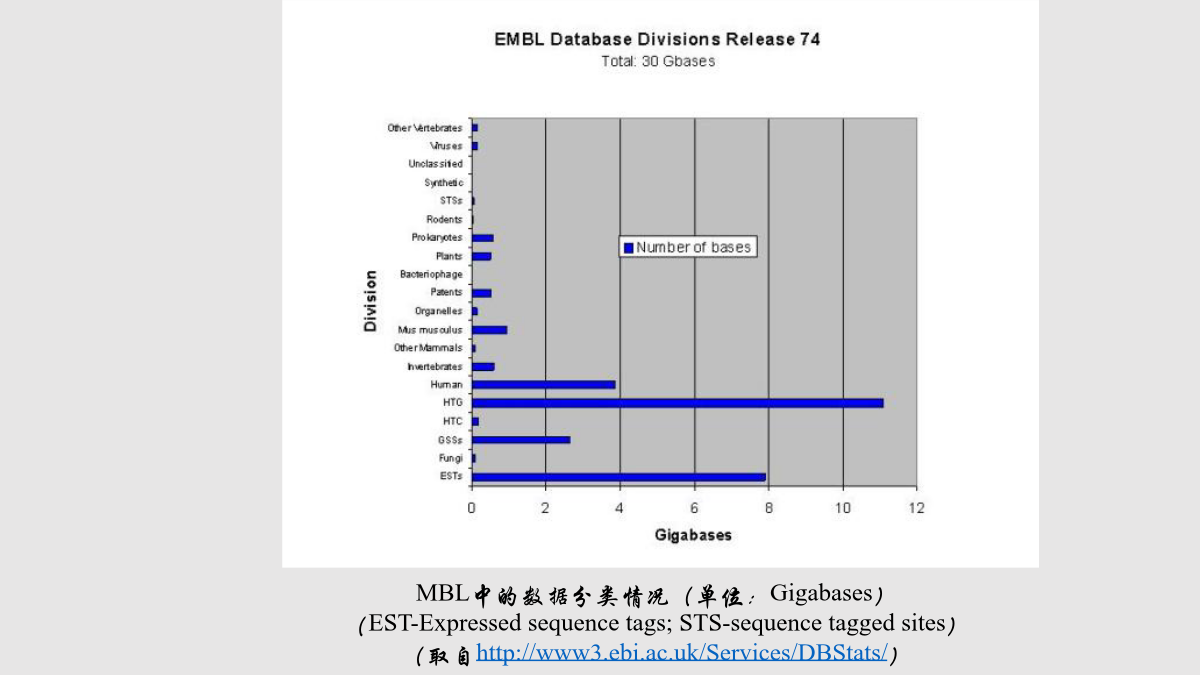
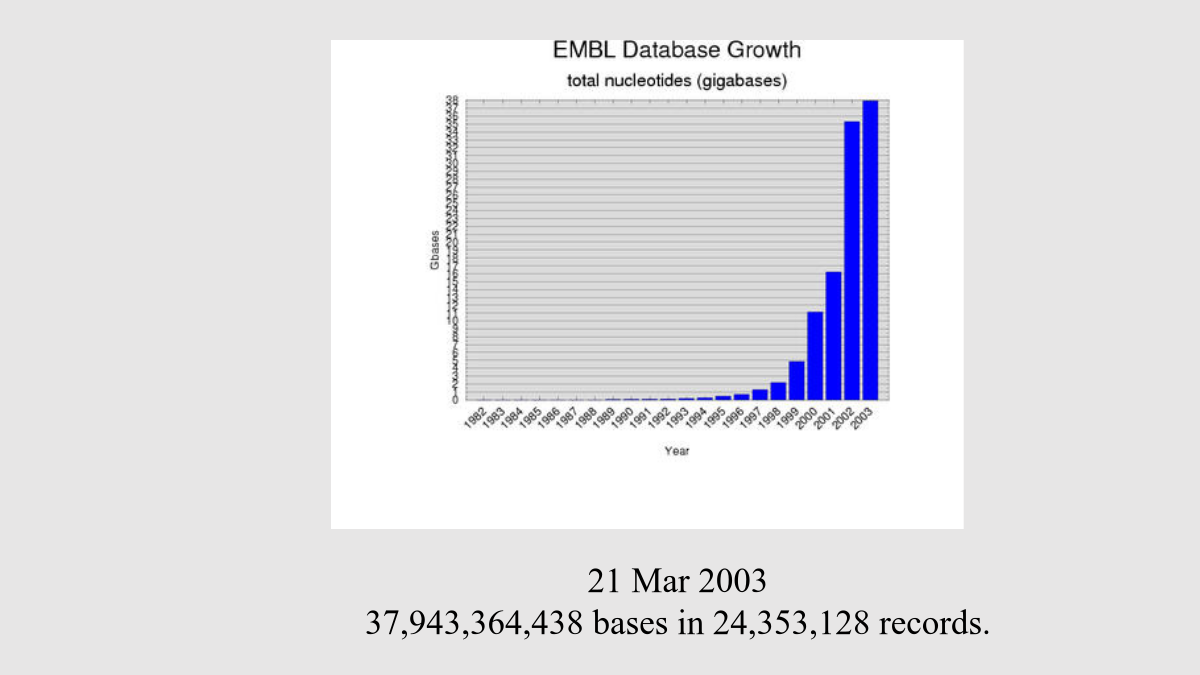
第四章生物分子数据库第一节引言生物分子数据库应满足5个方面的主要需求(1)时间性(2)注释(3)支撑数据(4)数据质量(5)集成性生物分子数据库一级数据库数据库中的数据直接来源于实验获得的原始数据,只经过简单的归类整理和注释二级数据库对原始生物分子数据进行整理、分类的结果,是在一级数据库、实验数据和理论分析的基础上针对特定的应用目标而建立的。生物分子数据库几个明显的特征:第二节核酸序列数据库核酸序列数据的增长趋势(纵轴代表总的核酸序列长度,单位:百万bp)“ID”为序列的标识符行,包括登录号、类型,分子的长度提交数据EMBL提供一些与序列相关的检索操作(基于3W服务器)例如:登录号为J00231的核酸序列具有这样一个交叉索引行:2、基因组数据库(GDB)与染色体相关的信息其它模式生物基因组数据库如:鼠基因组数据库MGD(http://www.informatics.jax.org/)酵母基因组数据库SGD(http://genome-www.stanford.edu/Saccharomyces/)Ensembl(http://www.ensembl.org/)Ensembl数据库结构图Ensembl提供多种查询方式通过关键字查询用BLAST进行相似序列的搜索另一种更直观的方式是显示各染色体用户可以在染色体水平上选择感兴趣的位点,逐层放大浏览整个基因组人的第9号染色体及大鼠对应的染色体片段4、表达序列标记数据库dbEST5、序列标记位点数据库dbSTS6、面向基因聚类数据库UniGene第三节蛋白质序列数据库除了蛋白质序列数据之外,PIR还包含以下信息:(1)蛋白质名称、蛋白质的分类、蛋白质的来源;(2)关于原始数据的参考文献;(3)蛋白质功能和蛋白质的一般特征,包括基因表达、翻译后处理、活化等;(4)序列中相关的位点、功能区域。PIR提供三种类型的检索服务:一是基于文本的交互式查询,用户通过关键字进行数据查询。二是标准的序列相似性搜索,包括BLAST、FastA等。三是结合序列相似性、注释信息和蛋白质家族信息的高级搜索,包括按注释分类的相似性搜索、结构域搜索等。三个子数据库2、SWISS-PROT(1)注释在SWISS-PROT中,数据分为核心数据和注释两大类。核心数据包括:序列数据、参考文献、分类信息(蛋白质生物来源的描述)注释包括:(A)蛋白质的功能描述;(B)翻译后修饰;(C)域和功能位点,如钙结合区域、ATP结合位点等;(D)蛋白质的二级结构;(E)蛋白质的四级结构,如同构二聚体、异构三聚体等;(F)与其它蛋白质的相似性;(G)由于缺乏该蛋白质而引起的疾病;(H)序列的矛盾、变化等。(2)最小冗余提交序列数据(a)编辑电子表格(b)利用Authorin程序(c)WWW服务器使用SWISS-PROT(a)CD-ROM形式(b)ftp服务器(c)Gopher服务器(d)WWW服务器(SRS)与序列相关的操作(a)序列查询(b)搜索同源蛋白质序列TrEMBL(http://www.ebi.ac.uk/trembl/index.html)是与SWISS-PROT相关的一个数据库。包含从EMBL核酸数据库中根据编码序列(CDS)翻译而得到的蛋白质序列,并且这些序列尚未集成到SWISS-PROT数据库中。TrEMBL有两个部分:(1)SP-TrEMBL(SWISS-PROTTrEMBL)包含最终将要集成到SWISS-PROT的数据,所有的SP-TrEMBL序列都已被赋予SWISS-PROT的登录号。(2)REM-TrEMBL(REMainingTrEMBL)包括所有不准备放入SWISS-PROT的数据,因此这部分数据都没有登录号。包括:Swiss-ProtTrEMBLPIR用户可以通过文本查询数据库,可以利用BLAST程序搜索数据库,也可以直接通过FTP下载数据。UniProt包含3个部分:(1)UniProtKnowledgebase(UniProt)蛋白质序列、功能、分类、交叉引用等信息存取中心(2)UniProtNon-redundantReference(UniRef)数据库将密切相关的蛋白质序列组合到一条记录中以便提高搜索速度;(3)UniProtArchive(UniParc)资源库,记录所有蛋白质序列的历史。第四节生物大分子结构数据库一种是显式序列信息(explicitsequence)在PDB文件中,以关键字SEQRES作为显式序列标记,以该关键字打头的每一行都是关于序列的信息。一种是隐式序列信息